
IRYSS MESSENGER
Turn Voice Messages Into
Interactive Conversations
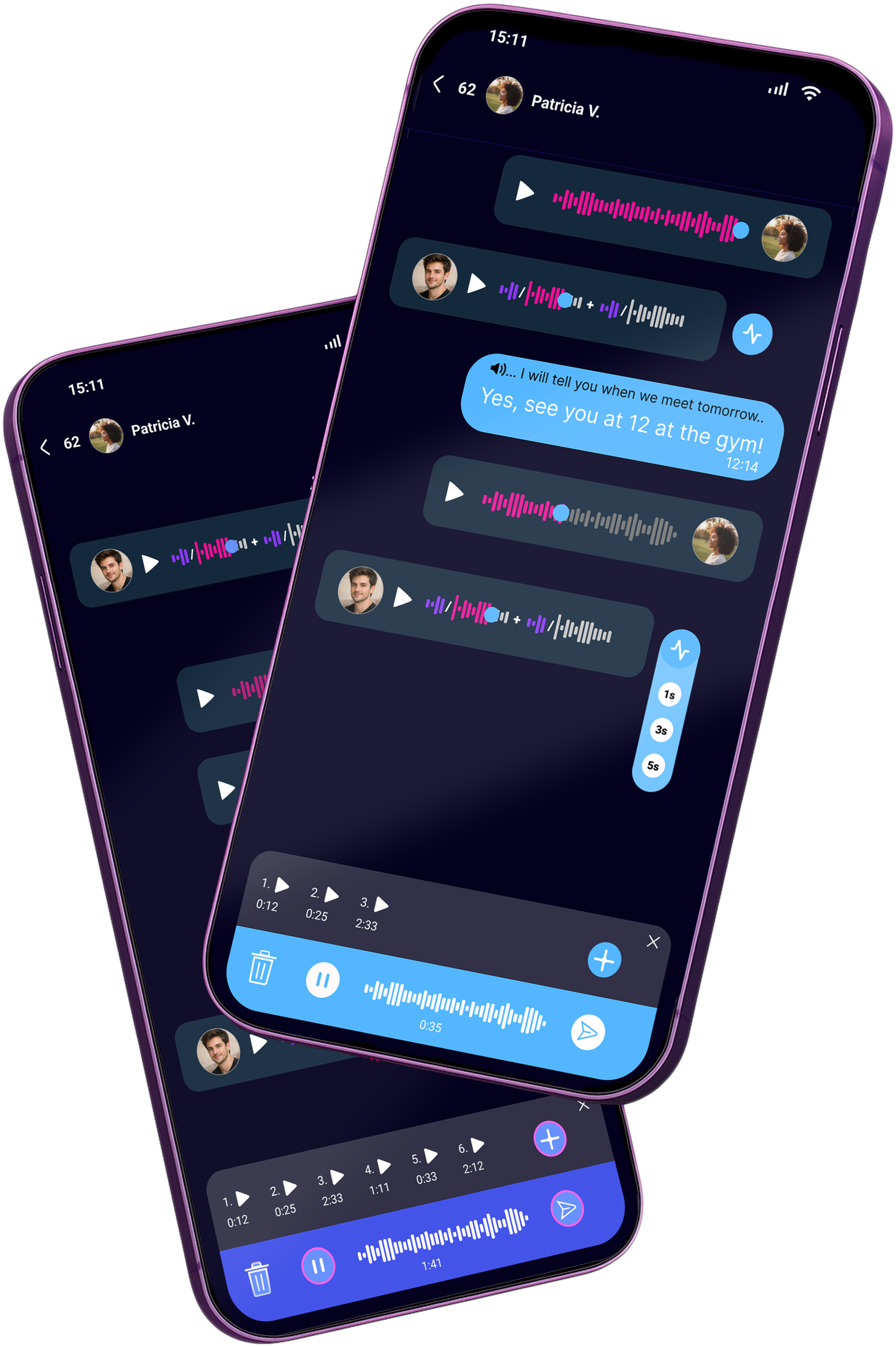
IRYSS transforms voice messages into time-anchored, context-preserving conversations.
● Discover the dynamic
Private Prototype Access

Instant Reaction
Capture emotion — even after the moment has passed.

Reaction Stack
Multiple reactions, stacked across a single message.

Context Anchoring
Replies attach to the exact moments in the conversation.